하둡에 대해서
안녕하세요 똑똑한 개발자에서 백엔드 개발을 하고 있는 김준성입니다. 동료의 추천으로 토스의 기술 컨퍼런스 slash21 을 접하여 내용을 들여다 보았습니다. link
토스의 백엔드는 어떻게 구성되어 있는 지에 대한 이야기였습니다. 떨리는 마음으로 이야기를 듣기 시작했는데 전혀 이해가 되지 않았습니다. 심지어 아는 단어도 하나 없었습니다. 으엥
그래서 해당 내용을 공부해 보았습니다.
.
.
본론
hadoop
하둡은 Java로 개발된 오픈소스 분산 클러스터 파일시스템입니다. 컴퓨터를 스케일링하는 과정에서 한대의 컴퓨터의 성능을 높일 수 있습니다. 한편으로는 여러대의 컴퓨터를 연결시켜 성능을 향상시킬 수 있습니다. 하둡은 후자를 가능하게 해주고 아마존, MS , Oracle 등 아주 큰 기업들에서 사용하고 있습니다. link
hadoop ecosystem
하둡은 다양한 하위 프로그램들로 구성되어있습니다. 하둡의 코어를 표현하는 방법은 다양하게 있으며 다음 사진은 그 중 하나입니다.
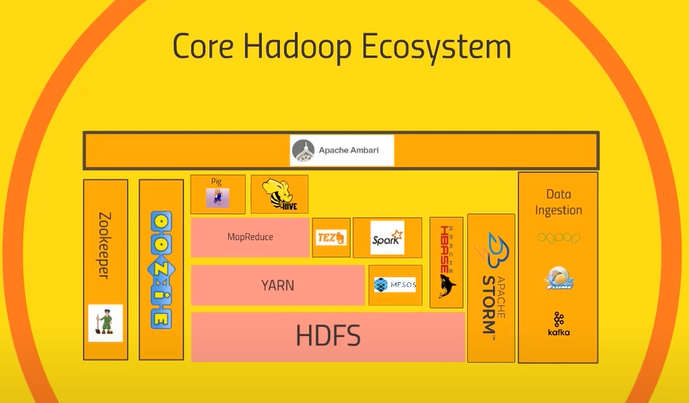
HDFS (hadoop ditributed file system)
하둡의 가장 기본이 되는 분산 파일 저장소 입니다. 정보를 여러대의 컴퓨터에 나눠서 관리할 수 있습니다.
Yarn (Yet another resource negotiator)
HDFS의 자원을 관리하는 프로그램입니다. 어떤 컴퓨터가 활성화 되어있는지를 확인하고 어떤 프로그램이 어디에서 언제 수행할 지 등을 관리합니다. 혈액을 받고 뿜어주는 심장과 같은 역할을 합니다.
MapReduce
map 기능과 reduce 기능이 있습니다. map기능은 데이터를 뽑아오는 일을 하고 reduce는 데이터를 통합하는 일을 합니다. 확장 가능성이 높습니다.
spark
map reduce 는 ‘디스크’에 데이터를 어떻게 분산하여 입출력하는가에 대한 해답입니다. mapReduce는 하부 컴퓨터의 디스크에 때문에 대용량의 데이터를 읽고 쓰는 데에 오랜 시간이 필요합니다. 이러한 문제를 해결하고자 spark가 등장하였습니다. spark는 하부 컴퓨터의 메모리에 데이터를 읽고 쓰는 방법을 채택하였습니다. 범용성이 넓고 스트리밍, sql 데이터 처리등을 할 수 있습니다. mapreduce와 spark 1 mapreduce와 spark 2
pig
Pig Latin 이라는 이름의 엔진으로 구조화된 데이터와 비구조화된 데이터에 사용할 수 잇습니다. map reduce 의 데이터 흐름을 통제하는 것은 개발자가 아닌 사람들이 사용하기에 매우 복잡합니다. 그래서 야후에서 내부 직원 모두가 빅데이터에 접근하기 쉽도록 sql 문과 비슷한 pig를 개발하였습니다. hdfs 외부에서 동작합니다.
Hive
HiveQl 이라는 이름의 sql engine으로 구조화된 데이터 사용에 적합합니다. map reduce 는 개발자가 아닌 사람들이 사용하기에 매우 복잡합니다. 그래서 Facebook에서 내부 직원 모두가 빅데이터에 접근하기 쉽도록 Hive를 개발하였습니다. hdfs 내부에서 동작합니다.
apache ambari
hadoop 전체의 상태를 관리하는 프로그램입니다.
mesos
yarn 처럼 hdfs 의 자원을 관리하는 프로그램입니다. yarn 과는 다른 방식을 사용하기 때문에 서로 장점과 단점이 있습니다.
Hbase
nosql database로 아주빠른 성능으로 OPTL 트랜스잭션을 처리하기 적합합니다. spark등 으로 가공된 데이터를 외부 웹에 전달하거나 외부 웹으로 부터 전달받기에 용이합니다.
apache strorm
아파치 스톰은 센서, 웹로그 등의 스트리밍데이터를 처리하기에 적합합니다.
OOZIE
클러스터 내부의 스케쥴링을 관리합니다. 몇시에 Hive에서 데이터를 뽑아오고 pig에 넣어 계산하는지 등 앱 간의 상호작용을 스케쥴링 할 수 있습니다.
Zookeeper
클러스터 내부 앱들의 상태관리를 합니다. 어떤 노드가 살아있는지 쓸 수 없는지 등을 관리합니다.
Data Ingestion
데이터 간
sqoop
하둡 클러스터와 외부 레거시 데이터 베이스(Mysql, mangoDb 등)를 연결시키는 역할을 합니다.
Flume
외부 웹서버로부터 실시간 웹로그를 받아 클러스터 내부로 옮겨주는 역할을 합니다.
Kafka
Flume과 같이 외부 소스로부터 데이터를 받아 클러스터 내부 프로세스에 뿌려주는 역할 을 합니다.
.
마치는 말
이상으로 하둡의 코어 시스템을 알아보았습니다. 하둡은 작은 컴퓨터를 모아 큰 컴퓨터를 만드는 작업이었습니다. 위의 내용이 상당히 추상화된 내용이라 이해하는데 힘이 드는 부분이 사실입니다. 그러나 이를 바탕으로 클라우드 컴퓨팅에 대한 이해를 시작을 할 수 있을 것 같습니다. 감사합니다.